1. 集群监控
1.1 Resource metrics pipeline图
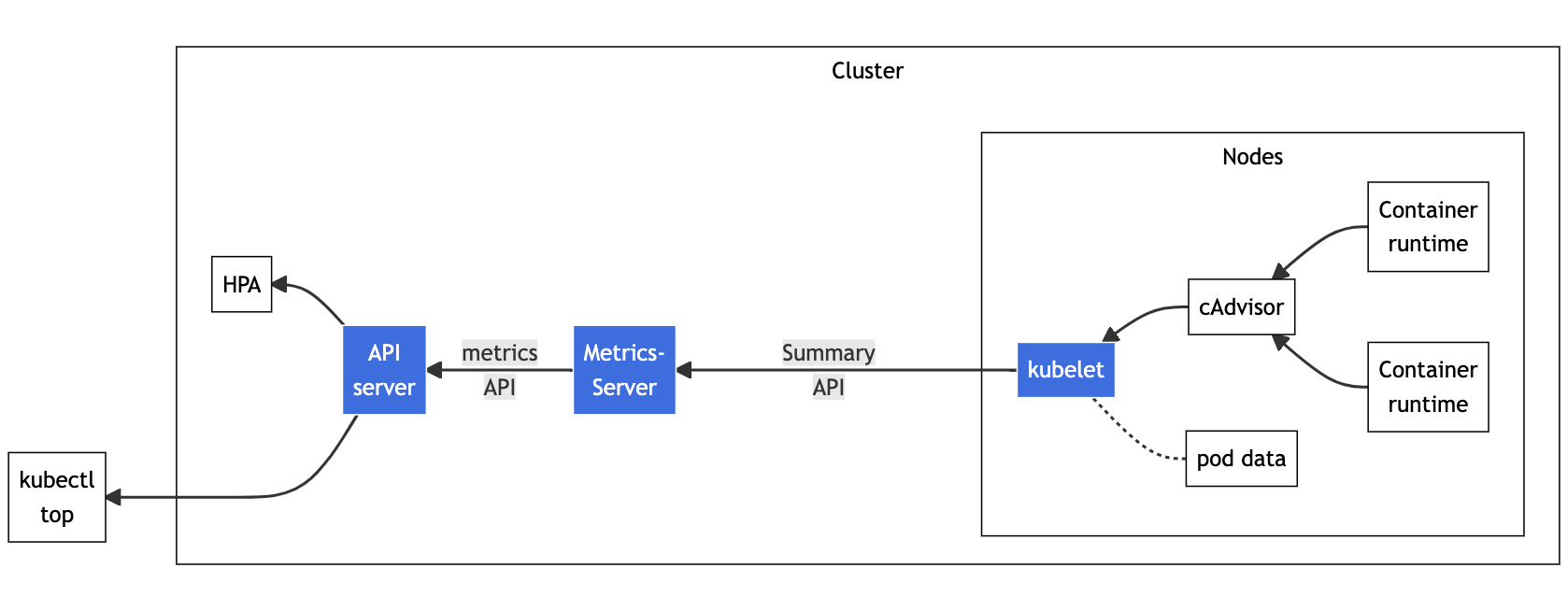
-
cAdvisor: 用于收集、聚合和公开Kubelet中包含的容器指标的守护程序。 -
kubelet: 用于管理容器资源的节点代理。 可以使用 /metrics/resource 和 /stats kubelet API 端点访问资源指标。 -
Summary API: kubelet 提供的 API,用于发现和检索可通过 /stats 端点获得的每个节点的汇总统计信息。 -
metrics-server: 集群插件组件,用于收集和聚合从每个 kubelet 中提取的资源指标。 API 服务器提供 Metrics API 以供 HPA、VPA 和 kubectl top 命令使用。Metrics Server 是 Metrics API 的参考实现。 -
Metrics API: Kubernetes API 支持访问用于工作负载自动缩放的 CPU 和内存。 要在你的集群中进行这项工作,你需要一个提供 Metrics API 的 API 扩展服务器。
1.2 安装Metrics Server
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 由于国内镜像
$ sed -i 's#image: registry.k8s.io/metrics-server/metrics-server:v0.6.3#image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.3#' components.yaml
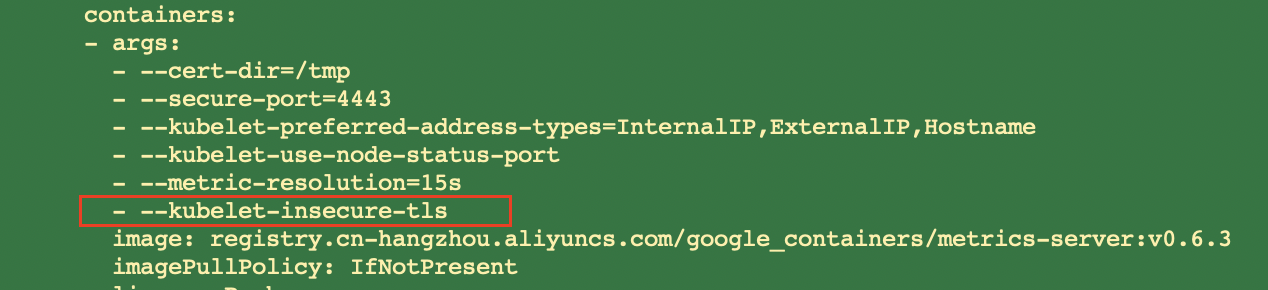
# 添加如下配置
- --kubelet-insecure-tls
$ kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
$ kubectl get pod -n kube-system |grep metrics-server
metrics-server-5d6946c85b-wkgwg 1/1 Running 0 53s
1.3查看集群信息
#查看本地kubectl和集群版本
$ kubectl version
# 查看集群信息
$ kubectl cluster-info
# 统计Node信息
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" |jq '.'
# 统计Node使用情况
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 303m 15% 1192Mi 64%
k8s-master2 230m 11% 1065Mi 57%
k8s-node1 105m 5% 933Mi 50%
# 查看node信息
$ kubectl get node -o wide
查看集群内部所有证书的过期时间
$ kubeadm certs check-expiration
2. 应用监控
# 统计pod的资源使用情况 kubectl top pod -n kube-system
$ kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-7bc6547ffb-2m6lc 2m 26Mi
calico-node-4dfgp 52m 140Mi
calico-node-7cslr 47m 126Mi
calico-node-7z9fz 43m 134Mi
coredns-6d8c4cb4d-7ztz7 5m 18Mi
coredns-6d8c4cb4d-b5z6n 3m 26Mi
# 描述pod的基本信息 kubectl describe pod
$ kubectl describe pod metrics-server-5d6946c85b-wkgwg -n kube-system
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 36m default-scheduler Successfully assigned kube-system/metrics-server-5d6946c85b-wkgwg to k8s-node1
Normal Pulled 36m kubelet Container image "registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.3" already present on machine
Normal Created 36m kubelet Created container metrics-server
Normal Started 36m kubelet Started container metrics-server
# 查看pod信息kubectl get pod {pod_name} -n {namespace} --watch
$ kubectl get pod calico-node-4dfgp -n kube-system --watch
NAME READY STATUS RESTARTS AGE
calico-node-4dfgp 1/1 Running 0 157m
# 查看namespace下的event信息kubectl get event
$ kubectl get event -n kube-system
LAST SEEN TYPE REASON OBJECT MESSAGE
38m Normal Scheduled pod/metrics-server-5d6946c85b-wkgwg Successfully assigned kube-system/metrics-server-5d6946c85b-wkgwg to k8s-node1
38m Normal Pulled pod/metrics-server-5d6946c85b-wkgwg Container image "registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.3" already present on machine
38m Normal Created pod/metrics-server-5d6946c85b-wkgwg Created container metrics-server
38m Normal Started pod/metrics-server-5d6946c85b-wkgwg Started container metrics-server
38m Normal SuccessfulCreate replicaset/metrics-server-5d6946c85b Created pod: metrics-server-5d6946c85b-wkgwg
48m Normal Scheduled pod/metrics-server-68cbdc9d4f-58k8z Successfully assigned kube-system/metrics-server-68cbdc9d4f-58k8z to k8s-node1
48m Normal Pulling pod/metrics-server-68cbdc9d4f-58k8z Pulling image "registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.3"
3. 其他监控
3.1 Prometheus & Grafana
https://github.com/prometheus-operator/kube-prometheus
由于国内网络原因,先在其他服务器下载所需所有的image,然后导入集群各个Node
# 其他服务器下载镜像
$ docker pull quay.io/prometheus/blackbox-exporter:v0.21.0
$ docker pull jimmidyson/configmap-reload:v0.5.0
$ docker pull grafana/grafana:8.5.5
$ docker pull k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
$ docker pull quay.io/prometheus/node-exporter:v1.3.1
$ docker pull quay.io/brancz/kube-rbac-proxy:v0.12.0
$ docker pull quay.io/prometheus-operator/prometheus-operator:v0.57.0
$ docker pull k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
$ docker pull quay.io/prometheus/prometheus:v2.36.1
$ docker pull quay.io/prometheus/alertmanager:v0.24.0
$ docker pull quay.io/prometheus-operator/prometheus-config-reloader:v0.57.0
# 其他服务器打包镜像
$ docker save quay.io/prometheus/blackbox-exporter:v0.21.0 -o kube_blackbox-exporter.tar
$ docker save jimmidyson/configmap-reload:v0.5.0 -o kube_configmap-reload.rar
$ docker save grafana/grafana:8.5.5 -o kube_grafana.rar
$ docker save k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0 -o kube_kube-state-metrics.rar
$ docker save quay.io/prometheus/node-exporter:v1.3.1 -o $ kube_node-exporter.rar
$ docker save quay.io/brancz/kube-rbac-proxy:v0.12.0 -o kube_kube-rbac-proxy.rar
$ docker save quay.io/prometheus-operator/prometheus-operator:v0.57.0 -o kube_prometheus-operator.rar
$ docker save k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1 -o kube_prometheus-adapter.rar
$ docker save quay.io/prometheus/prometheus:v2.36.1 -o kube_prometheus.rar
$ docker save quay.io/prometheus/alertmanager:v0.24.0 -o kube_alertmanager.rar
$ docker save quay.io/prometheus-operator/prometheus-config-reloader:v0.57.0 -o kube_prometheus-config-reloader.rar
# 将下载好的镜像上传到各个Node,并执行如下操作导入镜像
$ ctr -n=k8s.io image import kube_blackbox-exporter.tar
$ ctr -n=k8s.io image import kube_configmap-reload.rar
$ ctr -n=k8s.io image import kube_grafana.rar
$ ctr -n=k8s.io image import kube_kube-state-metrics.rar
$ ctr -n=k8s.io image import kube_node-exporter.rar
$ ctr -n=k8s.io image import kube_kube-rbac-proxy.rar
$ ctr -n=k8s.io image import kube_prometheus-operator.rar
$ ctr -n=k8s.io image import kube_prometheus-adapter.rar
$ ctr -n=k8s.io image import kube_prometheus.rar
$ ctr -n=k8s.io image import kube_alertmanager.rar
$ ctr -n=k8s.io image import kube_prometheus-config-reloader.rar
# 查看k8s.io命名空间下的images, crt是containerd的一个客户端工具,crictl是CRI(容器运行时)的命令行接口,kubernetes通过它来调用节点上的容器运行时,实现这个接口的可能是docker,也可能是containerd,也可能是podman。
$ crictl image
# 重命名其中的两个image
$ ctr -n=k8s.io image tag docker.io/grafana/grafana:8.5.5 grafana/grafana:8.5.5
$ ctr -n=k8s.io image tag docker.io/jimmidyson/configmap-reload:v0.5.0 jimmidyson/configmap-reload:v0.5.0
prometheus & grafana的安装
# 下载安装文件
$ git clone https://github.com/prometheus-operator/kube-prometheus.git
# 由于目标集群是1.23所以需要切换到适配的对应版本,具体对应版本可以参考github官方介绍
$ git checkout v0.11.0
# 安装prometheus和grafana
$ kubectl apply --server-side -f manifests/setup
$ kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
# 修改grafana的端口为nodeport
$ vi manifests/grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 8.5.5
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
nodePort: 31444
targetPort: http
selector:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
# 修改prometheus的端口为nodeport
$ vi manifests/prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.36.1
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
nodePort: 31445
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
selector:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: ClientIP
$ kubectl apply -f manifests/
# 移除网络限制
$ kubectl -n monitoring delete networkpolicies.networking.k8s.io --all
通过浏览器访问Grafana http://172.16.140.141/, 用户名admin, 密码admin
通过浏览器访问Prometheus http://172.16.140.141:31445/
卸载
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
3.2 其他监控
- Dynatrace https://www.dynatrace.com/
- NewRelic https://newrelic.com/
- Instana https://www.instana.com/
- 等等…
3.3 Kubernetes Dashboard UI
$ wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
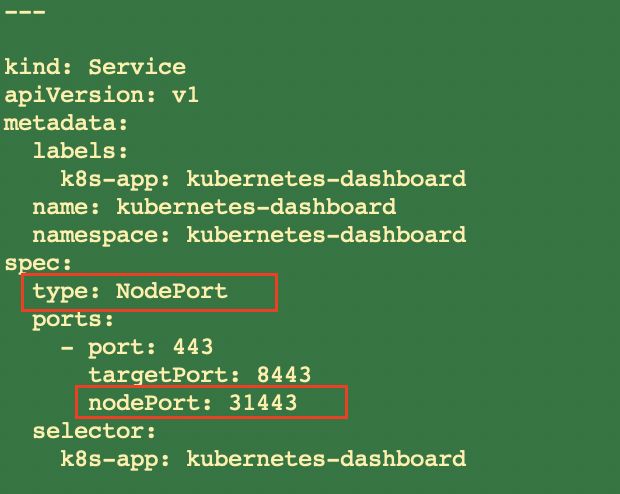
# 修改recommended.yaml中的内容,设置servicetype为NodePort并添加端口,如下图
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31443
selector:
k8s-app: kubernetes-dashboard
$ kubectl apply -f recommended.yaml
$ kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-6f669b9c9b-8bnpm 1/1 Running 0 4m2s
kubernetes-dashboard-758765f476-996cz 1/1 Running 0 4m2s
访问https://172.16.140.141:31443/
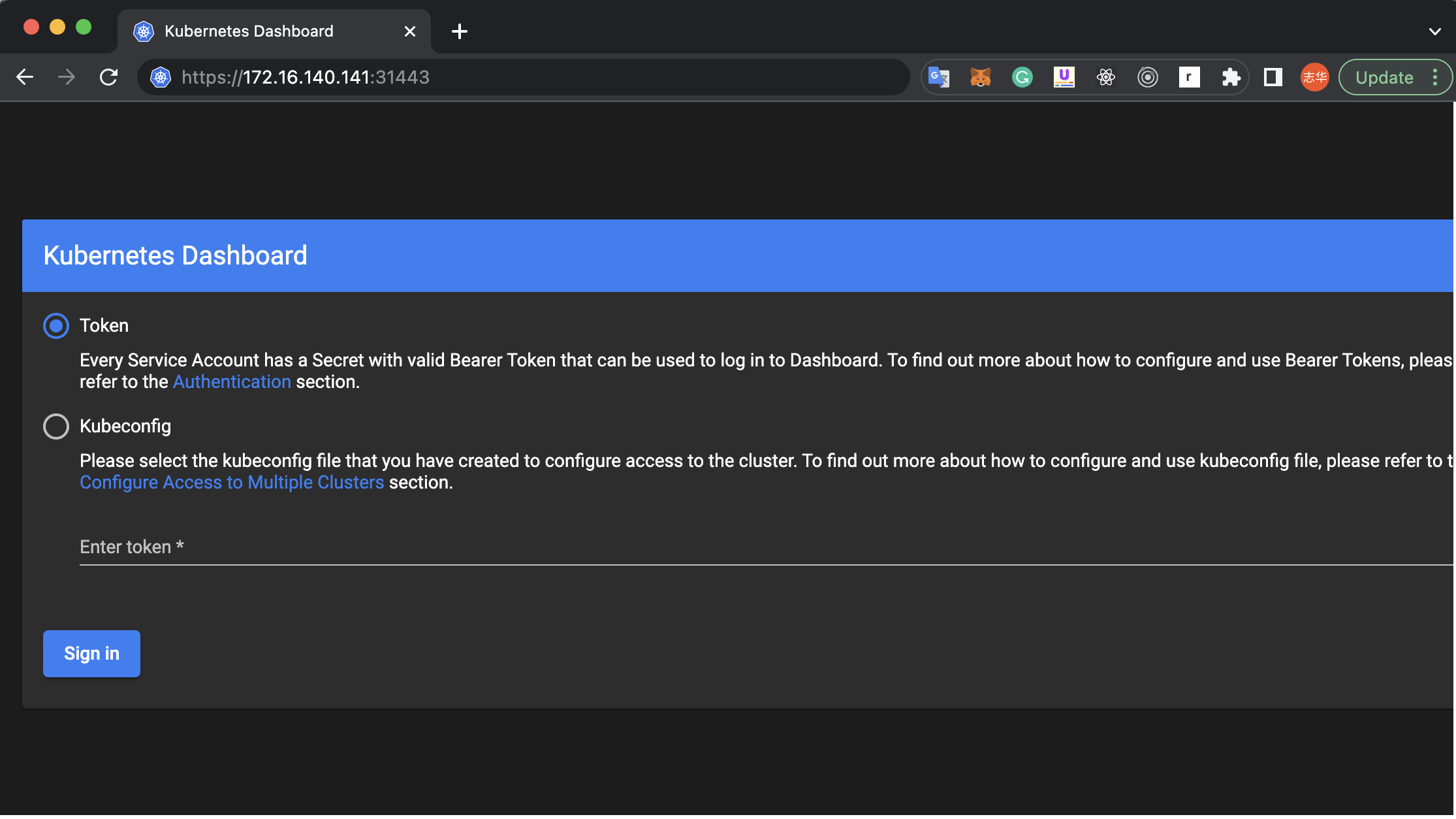
登录需要token或者kubeconfig,新建一个admin 账号
$ cat > dashboard-adminuser.yaml << EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
# 创建admin账号
$ kubectl apply -f dashboard-adminuser.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
# 查看admin账号的token
$ kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
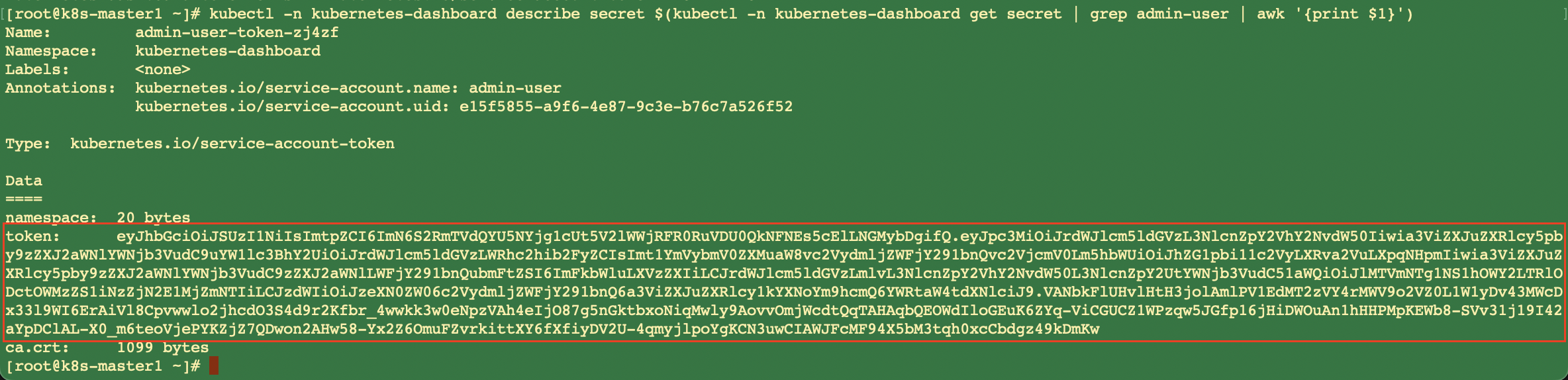
使用如上token登录之后如下图,就可以通过UI操作或监控整个Kubernetes集群了
4. 集群或组件日志管理
- kubelet运行日志
# 查看kubelet运行日志 $ journalctl -u kubelet - Kubernetes没有为集群级别的日志记录提供原生解决方案,但大概有三种方式可以查看集群或组件级别的日志
- 各组件(如api-server, scheduler, controller-manager等)是以pod方式运行,可以通过
kubectl logs查看所有pod日志,或者在目录/var/log/pods/中查看当前node上的pod的日志+ Sidecar模式,汇总日志并统一发送到日志服务器 - Daemonset在Node级别设置Agent进行收集所有日志,并汇总到统一的日志服务器
- 应用程序层解决,直接将日志发送到日志服务器
- 各组件(如api-server, scheduler, controller-manager等)是以pod方式运行,可以通过
5. 应用日志管理
# 查看pod的日志
$ kubectl logs {pod_name} -f -n {namespace}
# 查看deployment,statefulset, daemonset下所有pod的日志
$ kubectl logs -l{selector=tag} -f -n {namespace}
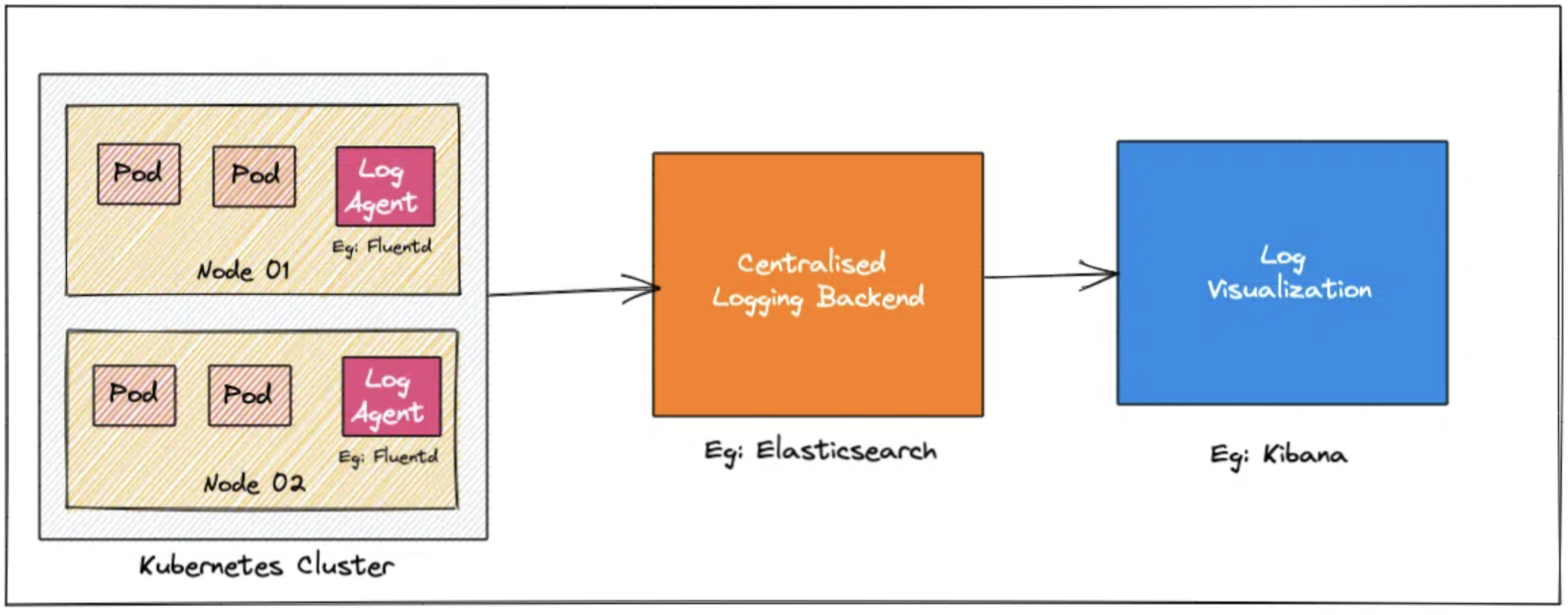
6. EFK(ElasticSearch, Fluentd, Kibana)