由于要从一个PDF中导出文档,而这个PDF为影印版,itextpdf完全不起作用,所以就想到了自动识别,搜索了下找到了这个由HP开发,Google改良的项目,由此可见,懒是一切进步的源泉!!不过最后的结果是识别效果不是很理想,需要自己训练。虽然结果不理想,但是学到了一些新的东西,所以记录下来,以备以后会用到。
介绍
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
安装
- 从http://download.csdn.net/detail/chenyangqi/9190667下载并解压。
- 双击解压文件中的tesseract-ocr-setup-3.02.02(1).exe执行安装过程。期间除了需要指定安装目录,其他都默认点下一步。
github上https://github.com/tesseract-ocr/tesseract有最新版本,Linux下的安装步骤。
测试
执行命令
# 其中第一个为命令本身,第二个为输入文件,第三个为输出文件
tesseract.exe d:\input.jpg d:\result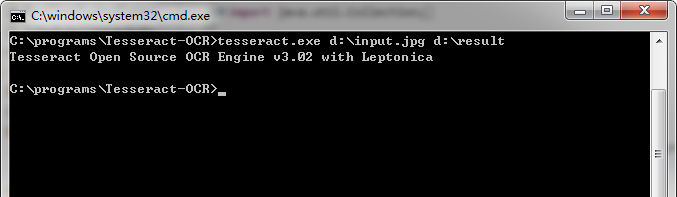
input.jpg

result.txt
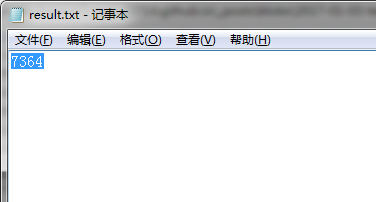
中文
以上测试针对中文和标点符号会出现乱码。安装目录的解决方法如下:
安装目录下的tessdata目录存放的是语言识别包,如果想增加中文识别功能,可以将中文的语言库放到此目录下,所以复制下载文件中的chi_sim.traineddata到安装的/tessdata目录.(更多语料可以到github官方地址下载)
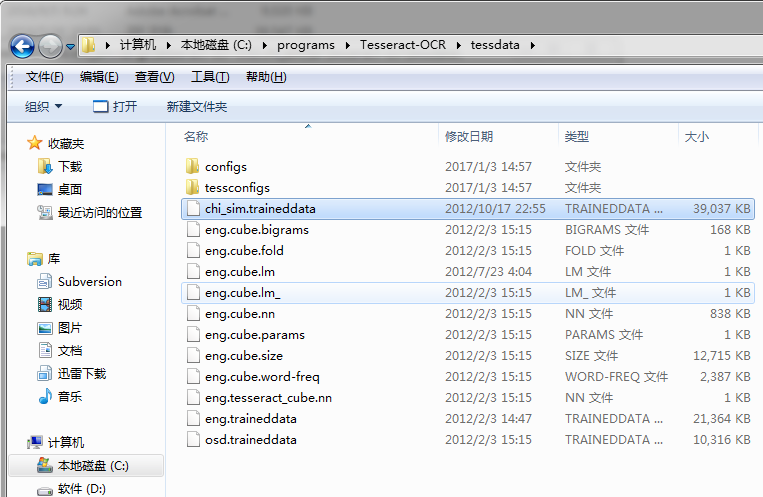
测试中文
执行命令
tesseract.exe d:\input_chinese.jpg d:\result_chinese -l chi_sim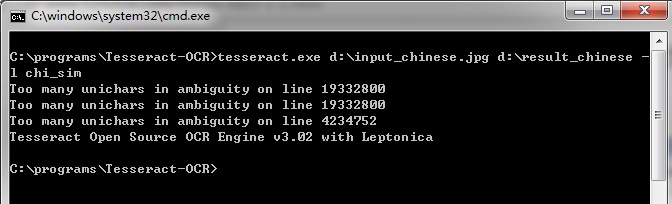
input_chinese.jpg

result_chinese.txt
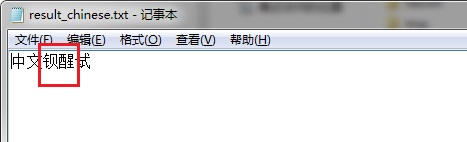
结论
从上述测试结果来看,不是很理想。
训练
参考资料
Tesseract-OCR引擎 入门 : http://blog.csdn.net/xiaochunyong/article/details/7193744/
Google下载(亲测已被墙) : http://tesseract-ocr.googlecode.com/files/tesseract-ocr-setup-3.01-1.exe
CSDN下载 : http://download.csdn.net/detail/chenyangqi/9190667
tesseract-ocr github : https://github.com/tesseract-ocr/tesseract