MapReduce默认配置
| InputFormat(输入) | TextInputFormat |
| MapperClass(Map类) | IdentityMapper |
| MapRunnerClass(Map启动类) | MapRunner |
| MapOutputKeyClass(Map输出Key类型) | LongWrite |
| MapOutputValueClass( Map输出Value类型) | Text |
| PartitionerClass(Partition类) | HashPartitioner |
| ReduceClass(Reduce类) | IdentityReduce |
| OutputKeyClass(输出Key类型) | LongWriteable |
| OutputValueClass(输出Value类型) | Text |
| OutputFormatClass(输出) | TextOutputFormat |
MapReduce Shuffle(洗牌)
Shuffle分为以下几个步骤:
- Combine
- Partition
- Merge
- Sort
- Copy
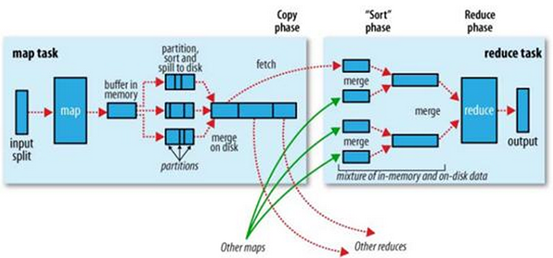
其中Map和Reduce之间的都是Shuffle的过程
MapReduce Combiner
- Combiner要解决的问题
- 当本地Map产生大量的输出,在传递给Reduce的过程中对带宽形成一定压力。
- Combiner是什么
- 作用是实现本地Key的聚合,对Map输出的Key排序,Value进行迭代,总结起来相当于一次本地的Reduce操作。减小Map输出,提升效率。
- 示例
- map:(key1,value1) ——> list(key2,value2)
- conbine:(key2,list(value2)) ——> list(key2,value2)
- reduce:(key2,list(value2)) ——> list(key3,value3)
- 慎用
- 当要求平均值的时候要慎用Combiners
- 并不是一定会被执行
- 如果当前集群在很繁忙的情况下job就是设置了也不会执行Combiner
- API
- 实现跟Reduce是一样的
Job.setCombinerClass(Class<? extends Reducer> cls)
MapReduce Partition
- Partition是什么
- Partition是对Map进行分拆,发给Reduce的过程
- Partition要解决的问题
- 当一个Map产生的数据要写入不同的文件,并且让这些操作并行执行。
- 应用场景:在对海量URL进行分析的时候,要对相同站点下的URL打散分拆处理。
- 示例
- job.setNumReduceTasks(int);
- 自定义Partition类,继承自Partitioner
- 实现public int getPartition(Text arg0, Text arg1, int reduceNumber);
- 返回值就是分发给第几个Reduce
- MapReduce提供的Partitioner
BinaryPartitioner: 是Partitioner的偏特化子类,该类提供LeftOffset和RightOffset, 在计算那一个Reduce的时候仅对Key的[LeftOffSet,RightOffSet]这个区间取HashKeyFieldBasedPartitioner: 提供多个区间取Hash,当区间数为0的时候,自动退化成为HashPartitionHashPartitioner<K, V>: 默认的Partitioner, 将map的结果发送到当前的Reducer计算策略为
public int getPartition(Object key, Object value, int numReduceTasks)
{
return (key.hashCode() & 2147483647) % numReduceTasks;
}
MapReduce作业调优
那些因素影响作业的效率
- Mapper的数量
- 尽量将输入数据切分成数据块的整数倍,如有太多小文件,考虑CombineFileInputFormat
- Reduce的数量
- 为了达到最高性能,急群众reduce数量应略小于reducer的任务槽数
- Combiner
- 充分使用合并函数减少Map和Reduce之间传递的数据量,Combiner在Map后运行
- 中间值的压缩
- 对Map输出值进行压缩减少到Reduce前的传递量
(conf.setCompressMapOutput(true)和setMapOutputCompressorClass(GzipCodec.class))
- 对Map输出值进行压缩减少到Reduce前的传递量
- 自定义序列
- 如果使用自定义的Writeable对象或自定义的Comparator, 则必须确保已经实现RawComparator
参考资料
Hadoop官方文档 : http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html
陆嘉恒 : 《Hadoop实战》 第2版