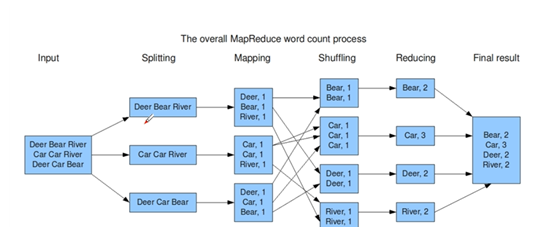
WordCount原理解析
文件清单
| WordCount.java |
| WordCountMapper.java |
| WordCountReduce.java |
WordCount.java
package com.freud.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* Entrance of the word count.
*
* @author freud
*
*/
public class WordCount {
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException {
// Get the hadoop configuration.
Configuration conf = new Configuration();
// Check the arguments.
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
/**
* Error if the argument length is not 2
*/
if (otherArgs.length != 2) {
System.out.println("Usage:wordcount <in> <out>");
System.exit(2);
}
// Instance a new job to run this program.
Job job = new Job(conf, "Word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// File input
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// File output
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// Run and exit
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}WordCountMapper.java
package com.freud.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
*
* Get the text line by line and then separate with " \t\n\r\f".
*
* @author freud
*
*/
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// Get the line value
String valueStr = value.toString();
// Separate the data。
StringTokenizer st = new StringTokenizer(valueStr);
// Write the map into context
while (st.hasMoreElements()) {
context.write(new Text(st.nextToken()), new IntWritable(1));
}
}
}WordCountReduce.java
package com.freud.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* Reducer class responsible for merge the same data in map.
*
* @author Freud
*
*/
public class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException {
// Count
int sum = 0;
while (value.iterator().hasNext()) {
sum += value.iterator().next().get();
}
// after merge the same data then set the map back.
context.write(key, new IntWritable(sum));
}
}运行
./hadoop jar Hadoop-Test-0.0.1-SNAPSHOT.jar com.freud.mapreduce.WordCount /home/hadoop-test/hadoop/input /home/hadoop-test/hadoop/output
参考资料
Hadoop官方文档 : http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html
陆嘉恒 : 《Hadoop实战》 第2版