图解
剖析MapReduce作业运行机制
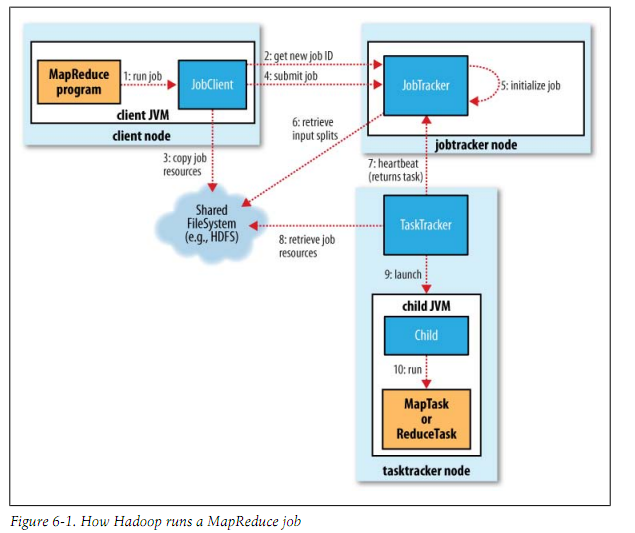
- 作业的提交 : 客户端通过JobClient.runJob()来提交一个作业到jobtracker,JobClient程序逻辑如下:
- 向Jobtracker请求一个新的job id (JobTracker.getNewJobId());
- 检查作业的输出说明,如已存在抛错误给客户端;计算作业的输入分片;
- 将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片)复制到jobtracker的文件系统中以jobid命名的目录下。作业jar副本较多(mapred.submit.replication = 10);
- 告知jobtracker作业准备执行 (submit job)。
- 作业的初始化
- job tracker接收到对其submitJob()方法的调用后,将其放入内部队列,交由job scheduler进行调度,并对其进行初始化,包括创建一个正在运行作业的对象(封装任务和记录信息)。
- 为了创建任务运行列表,job scheduler首先从共享文件系统中获取JobClient已计算好的输入分片信息,然后为每个分片创建一个map任务;创建的reduce任务数量由JobConf的mapred.reduce.task属性决定,schedule创建相应数量的reduce任务。任务此时被执行ID。
- 任务的分配
- jobtacker应该先选择哪个job来运行?这个由job scheduler来决定,下面会详细讲到。
- jobtracker如何选择tasktracker来运行选中作业的任务呢?
- 每个tasktracker定期发送心跳给jobtracker,告知自己还活着,是否可以接受新的任务。jobtracker以此来决定将任务分配给谁(仍然使用心跳的返回值与tasktracker通信)。每个tasktracker会有固定数量的任务槽来处理map和reduce(比如2,表示tasktracker可以同时运行两个map和reduce),由机器内核的数量和内存大小来决定。job tracker会先将tasktracker的map槽填满,然后分配reduce任务到tasktracker。
- jobtracker选择哪个tasktracker来运行map任务需要考虑网络位置,它会选择一个离输入分片较近的tasktracker,优先级是数据本地化(data-local)–>机架本地化(rack-local)。
- 对于reduce任务,没有什么标准来选择哪个tasktracker,因为无法考虑数据的本地化。map的输出始终是需要经过整理(切分排序合并)后通过网络传输到reduce的,可能多个map的输出会切分出一部分送给一个reduce,所以reduce任务没有必要选择和map相同或最近的机器上。
- 任务的执行
- tasktracker分配到一个任务后,首先从HDFS中把作业的jar文件复制到tasktracker所在的本地文件系统(jar本地化用来启动JVM)。同时将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。
- 接下来tasktracker为任务新建一个本地工作目录work,并把jar文件的内容解压到这个文件夹下。
- tasktracker新建一个taskRunner实例来运行该任务。TaskRunner启动一个新的JVM来运行每个任务,以便客户的map/reduce不会影响tasktracker守护进程。但在不同任务之间重用JVM还是可能的。子进程通过umbilical接口(?什么含义,暂时未知)与父进程进行通信。任务的子进程每隔几秒便告知父进程的进度,直到任务完成。
Streaming和Pipes是用来运行其它语言编写的map和reduce。Streaming任务特指任务使用标准输入输出steaming与进程通信,可以是任何语言编写的。pipes特指C++语言编写的任务,其通过socket来通信(persistent socket connection)。
- 进度和状态的更新
- 一个作业和每个任务都有一个状态信息,包括:作业或任务的运行状态(running, successful, failed),map和reduce的进度,计数器值,状态消息或描述。
- 这些信息通过一定的时间间隔由child JVM –> task tracker –> job tracker汇聚。job tracker将产生一个表明所有运行作业及其任务状态的全局试图。你可以通过Web UI查看。同时JobClient通过每秒查询jobtracker来获得最新状态。
- 作业的完成
- 作业的失败
作业的调度
- 默认调度器 – 基于队列的FIFO调度器
- 公平调度器(Fair Scheduler)- 每个用户都有自己的作业池,用map和reduce的任务槽数来定制作业池的最小容量,也可以设置每个池的权重。Fair Scheduler支持抢占,如果一个池在特定的一段时间内未得到公平的资源共享,它会中止运行池得到过多资源的任务,以便把任务槽让给运行资源不足的池。启动步骤:
- 拷贝contrib/fairscheduler下的jar复制到lib下;
- mapred.jobtracker.taskScheduler = org.apache.hadoop.mapred.FairScheduler
- 重启节点hadoop
- 能力调度器(Capacity Scheduler)
shuffle和排序
shuffle特指map输出后到reduce运行前得到输入的整个过程,它是MapReduce的心脏,属于不断被优化和改进的代码库的一部分,下面主要针对0.20版本。
- Map端
- Map输出首先放在内存缓冲区(io.sort.mb属性定义,默认100MB);
- 守护进程会将缓冲区的数据按照目标reducer划分成不同的分区(partition),同时按键进行内排序;如果客户端定义了combiner,则combiner会在排序后运行,继续压缩缓存区的数据;
- 缓冲区上定义了一个阈值(io.sort.spill.percent,默认为0.8),当存储内容达到这个值时,缓冲区的值会被写到本地文件中(mapred.local.dir定义,可以是一个或多个目录);这种文件会有多个,每个的内容都是按照reducer分区且局部排序的。这个过程简称spill to disk;
- Map输出完毕前,这些中间的输出文件会合并成一个已分区且已排序的输出文件中,合并会分多次,每次合并的中间文件个数有io.sort.factor来定义,默认是10;这个过程也会伴随着combiner的运行,min.num.spills.for.combine定义了运行combiner之前溢出写的次数;
- 写磁盘时可以压缩文件。mapred.compress.map.output设置为true,mapred.map.output.compression.codec指定压缩实现类;
- map任务完成后,会通知父tasktracker状态已更新,然后tasktracker通过心跳通知jobtracker。下面的reduce所在的tasktracker有一个线程定期询问jobtracker以便获得map输出的位置,直到它获得所有输出的位置。
- Reduce端
- 每个map任务的完成时间可能不同,但只要有一个任务完成,reduce任务得知后就开始复制对应它的输出,复制线程数由mapred.reduce.parallel.copies定义,默认为5;
- 如果map输出相当小,则不用复制到文件中,而是reduce tasktracker的内存中。缓冲区大小由mapred.job.shuffle.input.buffer.percent定义用于此用途的堆空间的百分比,默认0.7;一旦内存缓冲区达到阈值大小(由mapred.iob.shuffle.merge.percent,默认值为0.66)或达到reduce输出阈值(mapred.inmem.merge.threshold,默认值为1000),则合并后溢出写到磁盘中;
- 随着磁盘上副本的增多,后台线程会将它们合并为更大的排好序的文件。为了合并,压缩的map输出必须在内存中被解压缩;
- 复制完所有的map输出后,reduce任务进入合并阶段(sort phase,合并多个文件,并按键排序)。io.sort.factor定义了每次合并数,默认为10,即每10个map输出合并一次。会有很多个合并后的中间文件。
- 最后直接把中间文件数据输入给reduce函数,对已排序输出中的每个键都要调用reduce函数,此阶段的输出直接写到HDFS中。
- 配置的调优
- 总原则:给shuffle过程尽量多提供内存空间,但也要确保map函数和reduce函数能得到足够的内存。
- 运行map和reduce任务的JVM内存大小有mapred.child.java.opts属性设置。
- 在map端,避免多次溢出写磁盘来获得最佳性能。计数器spilled.records计算在作业运行整个阶段中溢出写磁盘的记录数,大则表明写磁盘太频繁;
- 在reduce端,中间数据全部驻留在内存中就能得到最佳性能。如果reduce函数的内存需求不大,那么把mapred.inmem.merg.threshold设置为0,把mapred.job.reduce.input.buffer.percent设置为1会带来性能的提升。
任务的执行
- Hadoop发现一个任务运行比预期慢的时候,它会尽量检测,并启动另一个相同的任务作为备份,即“推测执行”(speculative execution)。
- 推测执行是一种优化措施,并不能使作业运行更可靠。默认启用,但可以单独为map/reduce任务设置,mapred.map.tasks.speculative.execution和mapred.reduce.tasks.speculative.execution。开启此功能会减少整个吞吐量,在集群中倾向于关闭此选项,而让用户根据个别作业需要开启该功能。
- Hadoop为每个任务启动一个新JVM需要耗时1秒,对于大量超短任务如果重用JVM会提升性能。当启用JVM重用后,JVM不会同时运行多个任务,而是顺序执行。tasktracker可以一次启动多个JVM然后同时运行,接着重用这些JVM。控制任务重用JVM的属性是mapred.job.reuse.jvm.num.tasks,它指定给定作业每个JVM运行的任务的最大数,默认为1,即无重用;-1表示无限制即该作业的所有的任务都是有一个JVM。
- 在map/reduce程序中,可以通过某些环境属性(Configuration)得知作业和任务的信息。
| mapred.job.id | 作业ID,如job_201104121233_0001 |
| mapred.tip.id | 任务ID,如task_201104121233_0001_m_000003 |
| mapred.task.id | 任务尝试ID,如attempt_201104121233_0001_m_000003_0 |
| mapred.task.partition | 作业中任务的ID,如3 |
| mapred.task.is.map | 此任务是否为map任务,如true |