- Connect插件
- FileSystem的问题Buffer
- NodeJs中子进程管理
- V8的垃圾回收机制与内存限制
- NodeJS内存泄漏监控插件
- Express
- Socket IO
- Express和ejs使用特别注意:
- 参考资料
Connect插件
Connect自身十分简单, 是Node的一个中间件框架,其作用是基于Web服务器做中间件管理。至于如何如何处理网络请求,这些任务通过路由分派给管理的中间件们进行处理。它的处理模型仅仅只是一个中间队列,进行流式处理而已,流式处理可能性能不是最优,但是却是最易于被理解和接受。基于中间件可以自由组合和插拔的情况,优化它十分容易。其中Express就是依赖Connect创建而成的。
- 中间件
Connect的中间件扮演的是跟http模块一样的角色,处理请求,然后响应客户端或是让下一个中间件继续处理。如下是一个中间件最朴素的原型:
function (req, res, next) {
// 中间件
}在中间件的上下文中,有着三个变量。分别代表请求对象、响应对象、下一个中间件。如果当前中间件调用了res.end()结束了响应,执行下一个中间件就显得没有必要。
- 流式处理
为了演示中间件的流式处理,我们可以看看中间件的使用形式:
var app = require(‘connect’)();
// Middleware
app.use(connect.staticCache());
app.use(connect.static(__dirname + '/public'));
app.use(connect.session());
app.use(connect.bodyParser());
app.use(function (req, res, next) {
// 中间件
});
app.listen(3001);Conncet提供use方法用于注册中间件到一个Connect对象的队列中,我们称该队列叫做中间件队列。
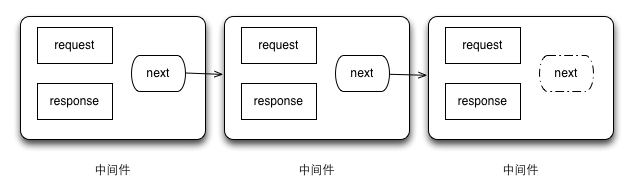
Connect通过use方法来维护一个中间件队列。然后在请求来临的时候,依次调用队列中的中间件,直到某个中间件不再调用下一个中间件为止。
值得注意的是,必须要有一个中间件调用res.end()方法来告知客户端请求已被处理完成,否则客户端将一直处于等待状态。
- 路由
其实app.use()方法接受两个参数,route和fn,既路由信息和中间件函数,一个完整的中间件,其实包含路由信息和中间件函数。路由信息的作用是过滤不匹配的URL。请求在遇见路由信息不匹配时,直接传递给下一个中间件处理。
通常在调用app.use()注册中间件时,只需要传递一个中间件函数即可。实际上这个过程中,Connect会将/作为该中间件的默认路由,它表示所有的请求都会被该中间件处理。
中间件的优势类似于Java中的过滤器,能够全局性地处理一些事务,使得业务逻辑保持简单。
任何事物均有两面性,当你调用app.use()添加中间件的时候,需要考虑的是中间件队列是否太长,因为每一层中间件的调用都是会降低性能的。为了提高性能,在添加中间件的时候,如非全局需求的,尽量附带上精确的路由信息。
app.stack = [];
app.use = function(route, fn){
// …
// add the middleware
debug('use %s %s', route || '/', fn.name || 'anonymous');
this.stack.push({ route: route, handle: fn });
return this;
};- 静态文件中间件
var connect = require('connect');
var app = connect();
app.use(connect.static(__dirname + '/public')); - 缓存策略
app.use('/public', connect.static(__dirname + '/public', {maxAge: 86400000})); maxAge默认是0,即不缓存,单位为毫秒,以上设置为10年。
FileSystem的问题Buffer
在计算机内部,一个中文占2个字节,一个英文占1个字节。
JavaScript中对字符串长度的判断,这个length属性对调用者而言是相当友好的。
console.log("0123456789".length); // 10
console.log("零一二三四五六七八九".length); /10
console.log("\u00bd".length); // 1但是当读取文本文档的时候
var fs = require('fs');
var rs = fs.createReadStream('testdata.text',{bufferSize: 11});
var data = '';
rs.on("data", function (trunk){
data += trunk;
});
rs.on("end", function () {
console.log(data);
});如果这个文件读取流读取的是一个纯英文的文件,这段代码是能够正常输出的。但是如果我们读取的是中文,由于BufferSize是奇数,那就会出现一个字符被分配在两个trunk中的场景。输出就会变为乱码。
解决办法是设置编码格式为UTF-8,使中文字符自动补齐。
var rs = fs.createReadStream('testdata.text', {encoding: 'utf-8', bufferSize: 11}); 在NodeJs中仅支持如下编码:utf8, ucs2, ascii, binary, base64, hex,并不支持中文GBK或GB2312之类的编码,如果需要读取GBK等编码,需要用到其他插件,比如iconv-lite
NodeJs中子进程管理
当想在Node中简单地执行一个外部命令,并让Node获取命令的返回值时。比如,执行一个UNIX命令、脚本或者其他那些不能在Node里直接执行的命令。可以使用Node的子进程
var child_process = require(‘child_process')
var exec = child_process.exec;
var options ={
timeout: 1000,
killSignal: ‘SIGKILL'
};
exec(command,options,callback);exec的第一个参数是准备执行的shell命令字符串,第二个参数是一个回调函数。这个回调函数将会在exec执行完外部命令或者有错误发生时被调用。回调函数有三个参数:error,stdout,stderr,看下面的例子:
exec(‘ls',function(err,stdout,stderr){
//execute
});如果有错误发生,第一个参数将会是一个Error类的实例,如果第一个参数不包含错误,那么第二个参数stdout将会包含命令的标准输出。最后一个参数包含命令相关的错误输出。
Options 包含的内容:
- cwd —— 当前目录,可以指定当前工作目录。
- Timeout以毫秒为单位的命令执行超时时间,默认是0,即无限制,一直等到子进程结束。
- Encoding子进程输出内容的编码格式,默认值是”utf8”,也就是UTF-8编码。如果子进程的输出不是utf8,你可以用这个参数来设置,支持的编码格式有:
- maxBuffer指定stdout流和stderr流允许输出的最大字节数,如果达到最大值,子进程会被杀死。默认值是200*1024。
- killSignal当超时或者输出缓存达到最大值时发送给子进程的终结信号。默认值是“SIGTERM”,它将给子进程发送一个终结信号。通常都会使用这种有序的方式来结束 进程。当用SIGTERM信号时,进程接收到以后还可以进行处理或者重写信号处理器的默认行为。如果目标进程需要,你可以同时向他传递其它的信号(比如 SIGUSR1)。你也可以选择发送一个SIGKILL信号,它会被操作系统处理并强制立刻结束子进程,这样的话,子进程的任何清理操作都不会被执行。
V8的垃圾回收机制与内存限制
- Javascript的垃圾回收
- JavaScript使用垃圾回收机制来自动管理内存,ECMAScript没有暴露任何垃圾回收器的接口。我们无法强迫其进行垃圾回收,更无法干预内存管理
- V8限制
- Node基于V8设计,与其他语言不同的一个地方,就是其限制了JavaScript所能使用的内存(64位为1.4GB,32位为0.7GB),这也就意味着将无法直接操作一些大内存对象。
- 当然这个限制是可以打开的,类似于JVM,我们通过在启动node时可以传递–max-old-space-size或–max-new- space-size来调整内存限制的大小,前者确定老生代的大小,单位为MB,后者确定新生代的大小,单位为KB。这些配置只在V8初始化时生效,一旦 生效不能再改变
- V8堆构成
- 新生代内存区:大多数的对象被分配在这里,这个区域很小但是垃圾回特别频繁 老生代指针区:属于老生代,这里包含了大多数可能存在指向其他对象的指针的对象,大多数从新生代晋升的对象会被移动到这里
- 老生代数据区:属于老生代,这里只保存原始数据对象,这些对象没有指向其他对象的指针*
- 大对象区:这里存放体积超越其他区大小的对象,每个对象有自己的内存,垃圾回收其不会移动大对象*
- 代码区:代码对象,也就是包含JIT之后指令的对象,会被分配在这里。唯一拥有执行权限的内存区*
- Cell区、属性Cell区、Map区:存放Cell、属性Cell和Map,每个区域都是存放相同大小的元素,结构简单
- 垃圾回收机制
- 自动垃圾回收算法的演变过程中出现了很多算法,但是由于不同对象的生存周期不同,没有一种算法适用于所有的情况。所以V8采用了一种分代回收的策略,将内 存分为两个生代:新生代和老生代。新生代的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。分别对新生代和老生代使用不同的垃 圾回收算法来提升垃圾回收的效率。对象起初都会被分配到新生代,当新生代中的对象满足某些条件(后面会有介绍)时,会被移动到老生代(晋升)
NodeJS内存泄漏监控插件
- node-heapdump 具体使用请参见:https://github.com/bnoordhuis/node-heapdump
- node-memwatch 具体使用请参见:https://github.com/lloyd/node-memwatch
Express
基于Connector中间件的Web框架,做网站用
官网http://www.expressjs.com.cn/
Socket IO
消息推送框架,通过建立长连接进行消息推送。
Express和ejs使用特别注意:
- BodyParser已经被移出Express单独成立一个项目,需要单独安装
通常 POST 内容的格式是 application/x-www-form-urlencoded, 因此要用下面的方式来使用:
app.use(require('body-parser').urlencoded({extended: true}))- 与ejs结合的时候,Layout被移出Express,需要单独安装
npm install express-partialsvar partials = require('express-partials');在 app.set('view engine', 'ejs'); 下面添加 app.use(partials());
在需要引用模板的地方调用 layout:’模版名称’ 示例
app.get('/reg', function (req, res) {
res.render('reg', {
title: '用户注册',
layout: 'template'
});
});在ejs文件中定义<%-body%>就可以了
参考资料
W3cschool: http://www.w3cschool.cc/nodejs/nodejs-tutorial.html
InfoQ: http://www.infoq.com/cn/articles/what-is-nodejs
NodeJs官网:http://nodejs.org/
ByVoid: 《node.js开发指南》
田永强:《深入浅出nodejs》
浅谈V8引擎中的垃圾回收机制: http://www.html-js.com/blog/2514