NameNode和DataNode组成
NameNode
- 主要提供名称查询服务,它是一个jetty的服务器
- NameNode保存Metadata信息
- 文件ownership和permissions
- 文件包含那些块
- fsimage二进制文件,保存hdfs所有的文件和目录的元数据信息
- EditLog负责保存每次HDFS改动的日志
- NameNode会在启动的时候Merge fsimage和Editlog来得到最新的fsimage
- Block保存在那个DataNode(由DataNode启动时上报)
DataNode
- 保存Block
- 启动DataNode线程的时候会向NameNode汇报Block信息
- 通过向NameNode发送心跳保持与其联系(3秒一次),如果NameNode10分钟没有收到DataNode的心跳,则认为已经Lost,并Copy其上的Block到其他DataNode
- DataNode副本存放策略
- 第一个,放置在上传文件的Datanode,如果是集群外部提交,则随机挑选一台合适的上传
- 第二个,放置在与第一个副本不同的机架的节点上
- 与第二个副本相同集群的节点上
- 更多:随机一台DataNode
- Block默认64M,如果上传文件小于该值,仍然会开辟一个Block的MetaData内存,但是物理上不会占用64MB的空间
- 问题:对小文件的处理不是很占有优势,因为当文件越小,MetaData的信息就会越多,NameNode的内存使用率就越大
- 从这个理论来讲的话,Block越大越好,但是MapReduce计算的时候,最后会切分到Block级别进行计算,要保证并发的效率,就得Block越小,所以这个值是要靠业务来驱动的
- 数据损坏处理(CheckSum)DN会在文件创建3周(可配置)后验证其checksum,如果损坏,则复制Block达到预期设置的文件备份数
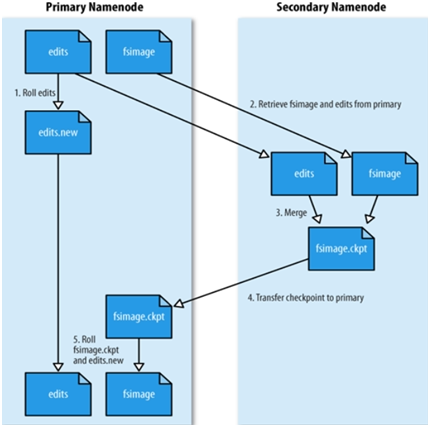
SecondaryNameNode
- 它不是NameNode的热备份
- 如果NameNode挂了,就挂了,没有办法
- 他可以作为冷备份
- 将本地保存的fsimage导入
- 修改cluster所有Data Node的NameNode地址
- 修改所有Client端Name Node地址
- 修改Secondary Name node IP为原Name Node IP地址
- SecondaryNameNode的备份有两种情况,是可配置的。
- 根据时间间隔(fs.checkpoint.period)默认1小时-3600(以秒为单位)
- 根据edits文件的大小(fs.checkpoint.size)默认64M- 67108864单位是byte http://blog.csdn.net/cheersu/article/details/8183052
- 它的工作是帮助NameNode合并Edits Log,减少NameNode启动时间,并对fsimage定期备份。
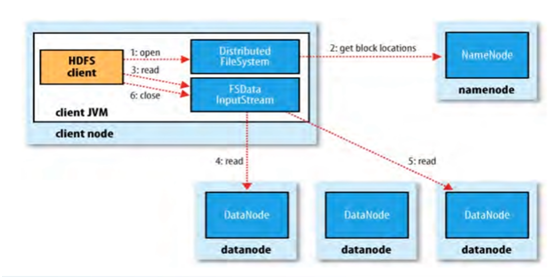
HDFS 读写讲解
- 读取
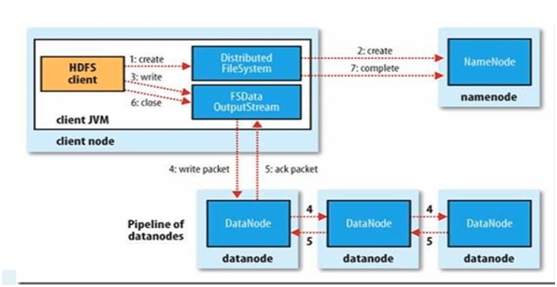
- 写入
HDFS 开发常用命令
- 创建一个文件夹
Hadoop fs –mkdir ***- 上传一个文件put
Hadoop fs –put <local_dir> <remote_dir>- 删除一个文件和文件夹
Hadoop fs –rm ***
Hadoop fs –rmr ***- 查看一个文件夹有哪些内容
Hadoop fs –ls ***- 查看某个文件的内容
Hadoop fs –cat ***HDFS API
- Create File - 创建文件
./hadoop jar Hadoop-Test-0.0.1-SNAPSHOT.jar com.freud.hdfs.MkdirSamplepackage com.freud.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* Mkdir Sample.
*
* @author Freud
*/
public class MkdirSample {
public static void main(String[] args) throws IOException {
// Get hadoop configuration
Configuration conf = new Configuration();
// Get file system
FileSystem fs = FileSystem.get(conf);
// Operation
fs.mkdirs(new Path("/user/test"));
}
}- Put File - 放入文件
./hadoop jar Hadoop-Test-0.0.1-SNAPSHOT.jar com.freud.hdfs.CopyFromLocalFileSystempackage com.freud.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* Copy file from local system to HDFS.
*
* @author Freud
*/
public class CopyFromLocalFileSystem {
public static void main(String[] args) throws IOException {
// Get hadoop configuration
Configuration conf = new Configuration();
// Get file system
FileSystem fs = FileSystem.get(conf);
// Operation
fs.copyFromLocalFile(new Path("/home/root/test/input.txt"), new Path(
"/user/hdfs/test/input.txt"));
}
}- Get File Location - 获得文件地址
./hadoop jar Hadoop-Test-0.0.1-SNAPSHOT.jar com.freud.hdfs.GetFilesLocationpackage com.freud.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* Get the file location in HDFS.
*
* @author Freud
*/
public class GetFilesLocation {
public static void main(String[] args) throws IOException {
// Get hadoop configuration
Configuration conf = new Configuration();
// Get file system
FileSystem fs = FileSystem.get(conf);
// Get File status
FileStatus fStatus = fs.getFileStatus(new Path(
"/user/hdfs/test/input.txt"));
// Get the file saved block location informations
BlockLocation[] blockLocations = fs.getFileBlockLocations(fStatus, 0,
fStatus.getBlockSize());
// List all of the locations
for (int i = 0; i < blockLocations.length; i++) {
System.out.println("Block_" + i + "_at_["
+ blockLocations[i].getHosts()[0] + "]");
}
}
}- Get DataNode MetaData - 获得DataNode元数据
./hadoop jar Hadoop-Test-0.0.1-SNAPSHOT.jar com.freud.hdfs.GetAllDataNodespackage com.freud.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
/**
* Get all data nodes informations.
*
* @author Freud
*/
public class GetAllDataNodes {
public static void main(String[] args) throws IOException {
// Get hadoop configuration
Configuration conf = new Configuration();
// Get file system
DistributedFileSystem dfs = (DistributedFileSystem) FileSystem
.get(conf);
// Get DataNode informations
DatanodeInfo[] datanodes = dfs.getDataNodeStats();
// List all the data node informations
for (int i = 0; i < datanodes.length; i++) {
System.out.println("DataNode_" + i + "_at_["
+ datanodes[i].getHostName() + "]");
}
}
}
参考资料
Hadoop官方文档 : http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html
陆嘉恒 : 《Hadoop实战》 第2版