Hadoop安装准备工作
安装JDK
- 下载Oracle JDK 官网下载地址
tar -zxvf jdk-8u40-linux-x64.tar.gzmkdir /usr/local/jdkmv jdk-8u40-linux-x64 /usr/local/jdk -rfvi /etc/profile最后面加入:
JAVA_HOME=/usr/local/jdk
export JRE_HOME=/usr/local/jdk/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATHsource /etc/profilejava -version查看当前Java版本是不是1.8
SSH免密码登录
ssh-keygen -t rsa集群需要把第一个的~/.ssh/authorized_keys拷贝到其他的服务器,保证互相之间可以免密码登录
.ssh目录的权限必须是700
.ssh/authorized_keys文件权限必须是600
为所有集群中的主机添加新用户
useradd hadoop
passwd hadoop修改计算机名称
cat /etc/sysconfig/network
hostname hadoop在/etc/hosts 文件中添加IP和主机名映射
通常为
*.*.*.1 hadoop.master
*.*.*.2 hadoop.slaver1
*.*.*.3 hadoop.slaver2
*.*.*.4 hadoop.slaver3关闭Selinux
修改/etc/selinux/config文件中设置SELINUX=disabled ,然后重启服务器。
关闭Iptables
chkconfig iptables offHadoop单机伪分布式安装
单机伪分布式1.*版本安装
- 修改conf/hadoop-env.sh
export JAVA_HOME=~/java/jdk1.7.0
export HADOOP_HOME=~/Hadoop-1.0.2
export PATH=$PATH:$HADOOP_HOME/bin- 修改conf/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://{NameNode_hostname}:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/hadoop-${user.name}</value>
</property>
</configuration>- 修改conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>- 修改conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>{JobTracker_hostname}:9001</value>
</property>
</configuration>- 常用配置参考 - Hadoop常用配置
- 格式化namenode
hadoop namenode -format 普通的2.*版本安装
- 按照1.的方式修改/etc/hadoop/文件的内容
如果在${hadoop_home}目录下存在conf,则会优先加载conf目录的配置(为了对1.*的兼容) http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-common/ClusterSetup.html
- Cloudera Manager安装 参照另一文档:<hadoop (二) - cloudera 5.0.1 安装>
Hadoop Cluster安装
- 所有服务器的Hadoop用户必须相同
- 必须开启SSH免密码登录
- Hadoop存放路径相同(将NameNode的Hadoop平行拷贝到其他服务器)
- 修改conf/slaves文件添加DataNode的hostname
- 修改conf/masters文件添加SecondaryNameNode的HostName
- 通过NameNode的bin/start-all.sh开启

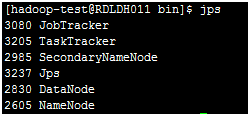
- 然后在每台服务器用jps查看是否每个服务正确启动
参考资料
Hadoop官方文档 : http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html
陆嘉恒 : 《Hadoop实战》 第2版